GPT5, Kimi K2, Horizon Beta - AI Benchmarks vs Reality
Why top-performing models on benchmarks often fail in real-world software development
The AI world loves its benchmarks
Every new model drops with flashy charts showing crazy high scores on tests like MMLU or HumanEval. GPT-5 hits 94.6% on AIME 2025. Kimi K2 gets 53.7% on LiveCodeBench, beating other models. Horizon Beta claims 95.0% accuracy in coding tests.
Sounds impressive, right? But here's the thing: these numbers don't tell you how these models actually work when you're trying to build real stuff.

It's better to test AI models hands on
At Kyln, we decided to test these hot new models on real work — the kind of stuff our clients actually need. We threw various coding tasks at GPT-5, and focused on UI work with Kimi K2 and Horizon Beta since everyone was saying they're great at frontend stuff.
GPT-5: Overhyped and Underwhelming
Let's be honest, GPT-5 was a disappointment. Despite all the fancy benchmark scores, it's painfully slow and just doesn't get coding right. We do appreciate GPT5 for its ability to make good documentation and planning steps of a task but... the implementation of the code is subpar compared to what Anthropics Sonnet can do.
Fun Fact!
Claude Opus is very high up on benchmark scores, but in real world situations, as an AI assistant to a software engineer, it just doesn't deliver. Not only is it slow, grossly expensive, but the code itself isn't great or deviates from the instructions.
At Amsterdam Standard we gain our highest performance boost with Claude Sonnet 4.0. Sometimes in the thinking version.
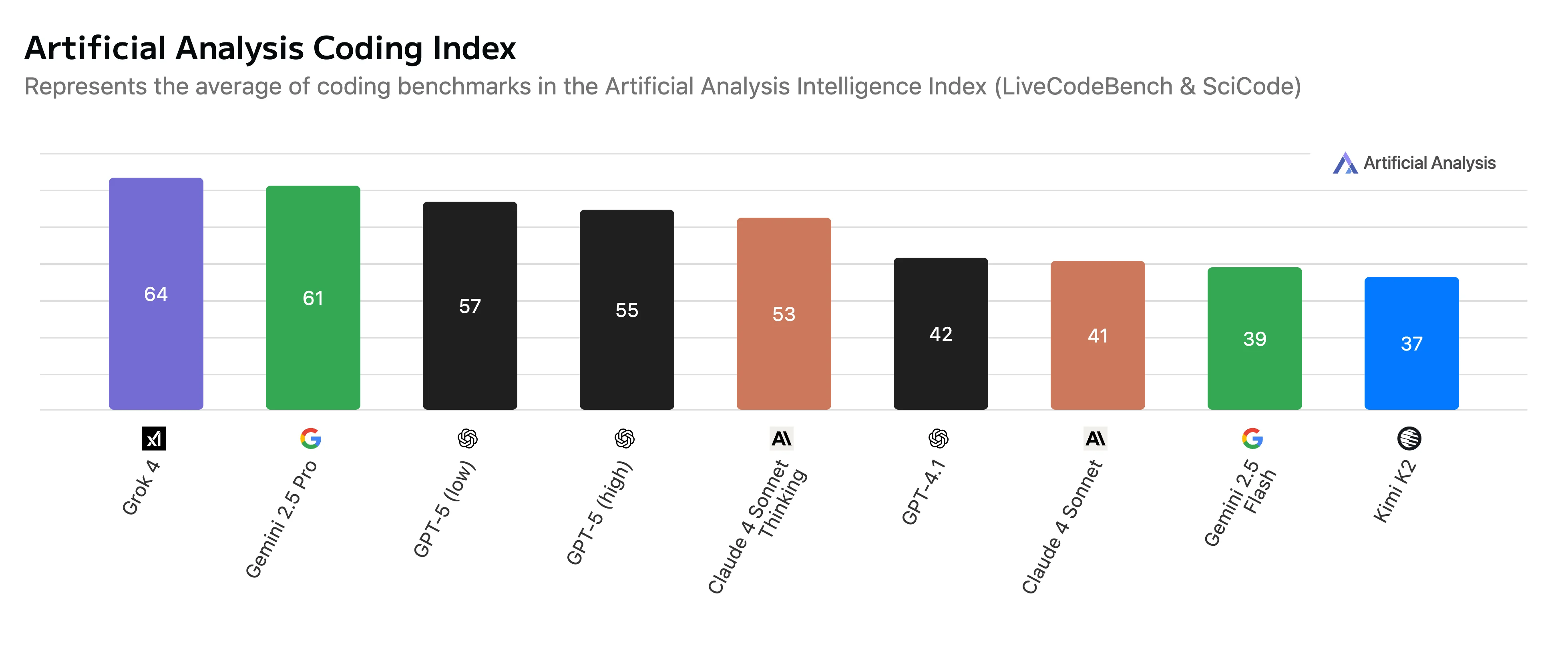 Even though our favorite scores only 41 points, we get actual results that we commit.
Even though our favorite scores only 41 points, we get actual results that we commit.
Kimi K2 & Horizon Beta - free but...
Since AI costs are on the rise, and so is the growing debt of AI providers, we can only expect the costs of AI to go up. We do research to test free models as well.
2 promising players were supposed to be Kimi K2 and a "stealth" model named Horizon. Youtube influencers went mad over their capabilities and crowning them the top free coding models that are on par with Claude Sonnet.
I personally conducted some UI tests, along with the Figma MCP that I was testing at the time. To be fair, for a free model, it did OK. But just OK. Even though the numbers on the charts are similar to Claudes, actually using Claude in Cursor yielded far better results.
Claude: Still the Winner (Unfortunately for Our Budget)!
What This Actually Means for Your Team
Based on our testing, here's what we'd recommend:
1. Don't Chase the Cheapest Model
Free models seem great until you factor in the time you'll spend fixing their mistakes. Sometimes paying more upfront saves you money in the long run.
2. Good Docs > Good Models
Seriously, this is huge. A well-documented component library like ShadCN will make any AI model work better. Invest in your development setup, not just better AI subscriptions.
3. Different Models for Different Jobs
We use Claude for complex stuff, and might use a cheaper model for simple tasks. Don't try to use one model for everything.
4. Test Everything Yourself
Those benchmark scores are basically marketing. Test models on your actual work before making any decisions. What works great for academic tests might suck for your specific use case.
AI models are getting better fast, and new ones with crazy benchmark scores come out every week. Don't pick an AI model based on benchmark scores alone. Test it with your actual work, using your actual tools, on your actual projects.
How we refactor code with AI at Kyln?
For the kind of legacy modernization work we do at Kyln, we've learned that the right combination of model + tools + human expertise works best.
We utilize GPT or Google Gemini for making the documentation for our TaskForge Framework.
Afterwards we switch models to Claude for the actual task implementation.
This mix of context engineering and model switching helps us achieve up to 60% more efficient rewriting of old code, and modernising our clients' projects.